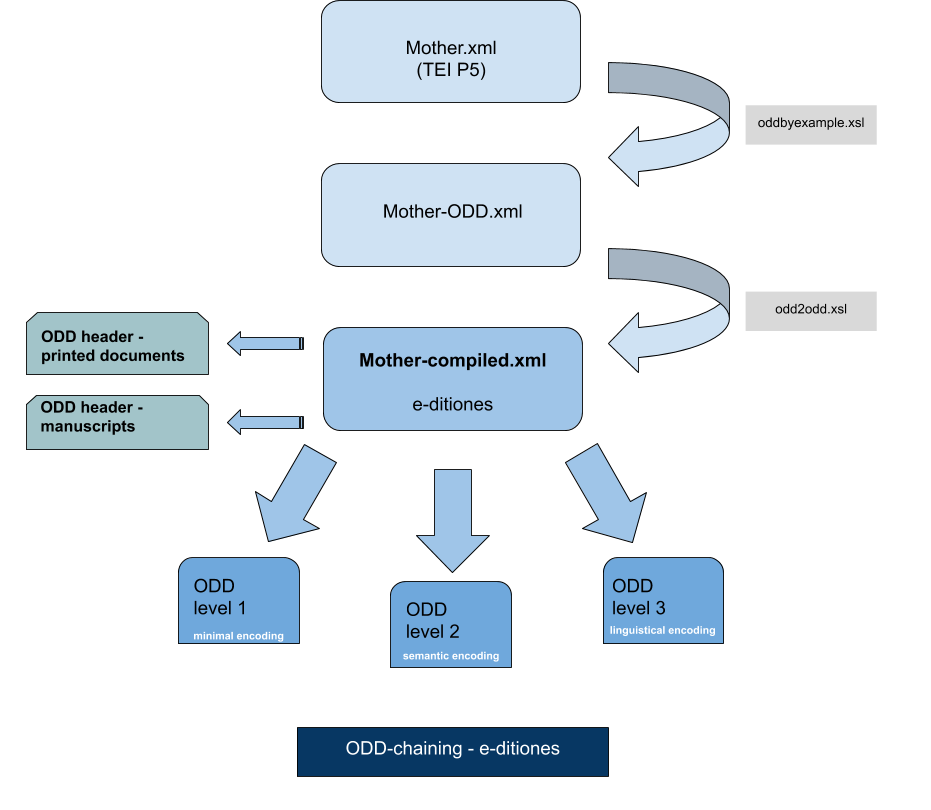
2.1. Headers encoding
First, we chose to identify two differents types of headers :
- manuscripts
- printed documents
Both headers are mostly the same : they contain a <fileDesc>, a <encodingDesc> and a <revisionDesc>. The only difference between the two of them is the addition of the <msDesc> used for the description of a manuscript.
<teiHeader>
<fileDesc>
</fileDesc>
<encodingDesc>
</encodingDesc>
<revisionDesc>
</revisionDesc>
</teiHeader>
2.1.1. The <fileDesc>
This part of the header contains at least five other parts :
- the <titleStmt>
- the <editionStmt>
- the <extent>
- the <publicationStmt>
- the <sourceDesc>
2.1.1.1. The <titleStmt>
This part is essential for the presentation of the encoded document. It has to contain at least one <title> and one <author>.
<titleStmt>
<title>Bérénice</title>
<author>Jean Racine</author>
</titleStmt>
2.1.1.2. The <editionStmt>
This part contains the name of the editor and the date of encoding.
<editionStmt>
<edition>
<date>30/04/2020</date>
</edition>
<respStmt>
<persName>Simon Gabay</persName>
<resp>Éditeur scientifique</resp>
</respStmt>
</editionStmt>
2.1.1.3. The <extent>
This part indicates the size of the work and contains the number of words and pages (considering that the number of pages equals the number of <pb>.
<extent>
<measure unit="words">12543</measure>
<measure unit="pages">99</measure>
</extent>
2.1.1.4. The <publicationStmt>
This part contains an <authority> element with the name of the project and an <availability> element with its status and the <licence>.
<publicationStmt>
<authority>e-ditiones</authority>
<availability status="restricted">
<licence target="https://creativecommons.org/licenses/by/4.0/">Attribution
4.0 International (CC BY 4.0)</licence>
</availability>
</publicationStmt>
2.1.1.5. The <sourceDesc>
This part contains one (or more) bibliographical description wich includes standards TEI elements such as <author>, <title> or <date>.
<sourceDesc>
<bibl>
<author>Jean Racine</author>
<title>Oeuvres</title>
<publisher>Jean Ribou</publisher>
<pubPlace>Paris</pubPlace>
<date when="1676">1676</date>
<ptr target="https://gallica.bnf.fr/ark:/12148/bpt6k990581p"/>
</bibl>
</sourceDesc>
2.1.1.5.1. The <msDesc>
As already said, there is a particularity when the text encoded is a manuscript. To describe the document, we have to use the <msDesc> element. To ensure a good encoding, severals elements are recommanded :
<msIdentifier> which contains informations used to properly identify the manuscript
<msIdentifier>
<country>Etats-Unis</country>
<settlement>Princeton</settlement>
<institution>Princeton University Library</institution>
<repository>Manuscripts Division, Department of Rare Books and
Special Collections</repository>
<collection>John Hinsdale Scheide Collection of Three Centuries of
French History</collection>
<idno type="shelfmark">C0710, vol. 3</idno>
</msIdentifier>
- <msContent> which contains informations about the intellectual content of the manuscript
<physDesc>which contains informations about the physical description of the document such as the <objectDesc> or the <bindingDesc>
<physDesc>
<objectDesc>
<supportDesc>
<support>
<objectType rend="composite">composite
repository</objectType>
<material>papier.</material>
</support>
<extent>
<measure unit="page" n="unk"/>
</extent>
<foliation>Pages aren't numebered</foliation>
</supportDesc>
</objectDesc>
<bindingDesc>
<binding>
<p/>
</binding>
</bindingDesc>
</physDesc>
- <history> which contains informations about the history of the manuscript
<additional>which contains more informations about the document, such as <surrogates> or bibliographical informations (<bibl>)
<additional>
<surrogates>
<graphic source="local" url="chemin"/>
</surrogates>
<listBibl>
<listBibl type="L1">
<bibl>La Fayette, <title>Œuvres complètes</title>, C.
Esmein-Sarrazin (éd.), Paris: Gallimard, lettre
n°70-1.</bibl>
</listBibl>
</listBibl>
</additional>
- <msPart> which might contain the preceding elements is used to the description of a specific part of the encoded manuscript
2.1.2. The <encodingDesc>
This part describes the relationship between the encoded text and its source. It might contain :
- <projectDesc> which describes the project
- <editorialDecl> which contains informations about the editorial principles such as <correction>, <normalization> or <interpretation>
<encodingDesc>
<projectDesc>
<p>Creation of a NLP tools for 17th French</p>
</projectDesc>
<editorialDecl>
<correction>
<p>Very minor corrections, usually tagged.</p>
</correction>
<hyphenation>
<p>Kept, encoded with <gi>c</gi>
</p>
</hyphenation>
<normalization>
<p>None</p>
</normalization>
<quotation>
<p>Original</p>
</quotation>
<punctuation>
<p>Original</p>
</punctuation>
<interpretation>
<p>None</p>
</interpretation>
<segmentation>
<p>Text is divided in <list>
<item>sentences encoded with <gi>s</gi>
</item>
<item>sub-sentences encoded with <gi>seg</gi> (most or the time based
on columns and semicolons)</item>
</list> and </p>
</segmentation>
</editorialDecl>
</encodingDesc>
2.1.3. The <revisionDesc>
This last part of the header contains informations about at least one <change> during the production of the document. when is used to specify the date of the event.
<revisionDesc>
<change when="20200430">Add documentation</change>
</revisionDesc>
2.2. Text encoding
After the OCR of the text, its encoding will be completed in three phases :
- Level 1 : the encoding will distinguish form and content
- Level 2 : we will add semantic informations
- Level 3 : we will add linguistical informations
Please note that at each level, all existing elements are still used and new elements are added to the existing ones.
2.2.1. First level
The purpose of the first level is to distinguish between form and content. To do that, we chose to only use a few elements. First, at all levels our edition must contain a <text> element with the following namespace : @xmlns="http://www.tei-c.org/ns/1.0". It checks the validation of the TEI schema.
Then, at this level of encoding, all the text is included in the <body> and in a single <p>. Some informations are added at this point : concerning the content of the text, the element <fw> contains informations such as title, pagination or editor's notes. The other informations added are about the form of the text. We decided to employ the elements <pb> and <lb>. The first one, <pb>, which marks the point where a new page begins, is useful in the way that it can be used to check the transcription but also to compare our edition with a reference edition. The second one, <lb>, which marks the point where a new line begins, provides graphical informations and can be used for an automatic encoding process. It has two required attributes : break and rend. If a word is cut at the end of a line, break with the value "no" is useful in that the complete word can be establish again and be considere as a token. @rend shows which mark is used (a dash or an hyphen for example).
<text xml:id="EDI_0001">
<body>
<lb/>
<fw>A MONSEIGNEVR LE DVC D’ESPERNON. <lb/>Lettre I.</fw>
<p>
<lb/>Monseignevr, Quand ie ne ſerois pas nay cõme ie ſuis, voſtre
<lb/>tres-humble ſeruiteur, il faudroit que ie fuſſe mauuais <lb/>François
pour ne me reſioüir pas des contẽtemens de voſtre maiſon, <lb/>puis que ce
ſont des felicités publiques.</p>
</body>
</text>
2.2.2. Second level
At this level of encoding, we add manually some semantic informations. Considering that we want to use, as mentioned before, a minimal set of elements, we decided to only employ common elements. Despite this, in the case of texts such as plays or letters, the use of a few specific elements is recommended.
2.2.2.1. Common elements
It is possible to use the following elements :
| Element | Text type | Note |
| <front> | any prefatory matter | |
| <div> | any text subdivision | type,n and xml:id are required |
| <back> | any type of appendix | |
| <head> | any type of heading | this can be used to clarify <fw> |
| <list>and<item> | any type of list | n and xml:id are required |
| <orgName>, <persName> and <placeName> | any type of person, place or organisation | this can be useful for entity search |
| <l> and <lg> | any type of line or line group | |
| <note> | any type of note | it can be used for a note by the autor, the editor or, rarely, added during the encoding |
2.2.2.2. Specific elements
There are only two exceptions, drama and letters.
2.2.2.2.1. Drama
If the text encoded is a play, it is allowed to use three new elements :
| Element | Text type | Note |
| <sp> | contains a speech | n and xml:id are required |
| <stage> | any stage direction | e.g. useful to study spoken words |
| <speaker> | any speaker in a speech | |
<text xml:id="EDI_0001">
<body>
<div type="letter" xml:id="EDI_0001-1"
n="1">
<head>A <persName>MONSEIGNEVR LE DVC D’ESPERNON</persName>.
<lb/>Lettre I.</head>
<p n="1" xml:id="EDI_0001-1-1">
<persName>Monseignevr</persName>, Quand ie ne ſerois pas nay cõme
ie ſuis, voſtre tres-humble ſeruiteur, il faudroit que ie fuſſe
mauuais François pour ne me reſioüir pas des contẽtemens de voſtre
<orgName>maiſon</orgName>, puis que ce ſont des felicités
publiques. <lb/>Nous auõs ſçeu l’heureux ſuccés du voyage que vous
auez fait en <placeName>Bearn</placeName>
</p>
</div>
</body>
</text>
Example of a letter
<body>
<div type="play" xml:id="EDI_0002-1" n="1">
<head>
<lb/>L’ILLVSION <lb/>COMIQVE <lb/>COMEDIE</head>
<div type="act" xml:id="EDI_0002-1-1"
n="1">
<lb/>
<head>ACTE PREMIER.</head>
<div type="scene"
xml:id="EDI_0002-1-1-1" n="1">
<lb/>
<head>SCENE PREMIERE.</head>
<lb/>
<stage>
<persName>PRIDAMANT</persName>,
<persName>DORANTE</persName>.</stage>
<lb/>
<sp n="1" xml:id="EDI_0002-1-1-1-1">
<speaker>DORANTE.</speaker>
<p n="1" xml:id="EDI_0002-1-1-1-1-1">
<lb/>CE grand Mage dont l'art commande <lb/>à la nature
<lb/>N'a choiſi pour palais que cette grotte <lb/>obſcure;
<lb/>La nuit qu'il entretient ſur cet af <lb break="no" rend="¬"/>freux ſeiour <lb/>N'ouurant ſon voile espais
qu'aux raions d’vn <lb/>fauxiour, <fw>
<lb/>A <lb/>2 L’ILLVSION COMIQ.</fw>
<lb/>De leur eſclat douteux n'admet en ces lieux ſombres
<lb/>Que ce qu'en peut ſouffrir le commerce des ombres.
<lb/>N'auances pas, ſon art au pied de ce Rocher <lb/>A mis
dequoy punir qui s'en oſe approcher, <lb/>Et cette large
boucbe eſt vn mur inuiſible, <lb/>Ou l'air en ſa faueur
deuient inacceßible, <lb/>Et luy fait vn rampart dont les
funestes bords <lb/>Sur vn peu de poußiere eſtalent mille
morts. <lb/>Ialoux de ſon repos plus que de ſa deffenſe
<lb/>Il perd qui l'importune ainſi que qui l'offence, <lb/>Si
bien que ceux qu'amene vn curieux deſir <lb/>Pour conſulter
<persName>Alcandre</persName> attendent ſon loiſir,
<lb/>Chaque iour il ſe monſtre, & nous touchons à l'heure
<lb/>Que pour ſe diuertir il ſort de ſa demeure.</p>
</sp>
</div>
</div>
</div>
</body>
Example of a speech
2.2.2.2.2. Letters
If the text encoded is a letter, it is allowed to use two new elements :
| Element | Text type | Note |
| <opener> | any text at the start of a letter | e.g. a salutation or a dateline |
| <closer> | any text at the end of a letter | e.g. a salutation or a dateline |
2.2.3. Third level
This level of encoding is automaticaly done. In order to add some linguistical informations, the original version of the text is normalized with the following elements : <choice>, <orig> and <reg>. Then, in order to process tokenization and lemmatization on the text, we decided to split it with <seg> and <w>. The first one, <seg> is used to represent any segmentation of the text. Note that sentences and clauses remain our basic units but we recommand to split a long sentence in several segments. The <w> is used to mark a single token. Regarding ponctuation, we decided to consider the marks as tokens; first, because more precision wouldn't be useful for our analyse and second, because with this choice, our encoding remains compatible with ELTeC.
<p n="1" xml:id="EDI_0002-1-1-1-1-1">
<choice>
<orig>
<seg>
<w>N</w>
<w>'</w>
<w>a</w>
<w>choiſi</w>
<w>pour</w>
<w>palais</w>
<w>que</w>
<w>cette</w>
<w>grotte</w>
</seg>
</orig>
<reg>
<w>N</w>
<w>'</w>
<w>a</w>
<w>choisi</w>
<w>pour</w>
<w>palais</w>
<w>que</w>
<w>cette</w>
<w>grotte</w>
</reg>
</choice>
</p>
2.3. The attributes
We decided to define a closed of attributes that can be used for the encoding. There are only three of them :
Please note that all of them are required.
2.3.1. xml:id
This attribute is used to identify the document or its subdivisions. Earlier in this document, we presented the way to properly generate identifiers.
xml:id is required on several elements and a diffetent levels :
| Element | Level of encoding |
| <text> | all levels |
| <div> | levels 2 and 3 |
| <p> | levels 2 and 3 |
| <sp> | levels 2 and 3 |
| <lg> | levels 2 and 3 |
| <l> | levels 2 and 3 |
2.3.2. n
This attribute is used to identify the numbering of its element from the second level. Node children elements are numbered incrementaly starting with 1.
Note that there are two exceptions :
- <pb> : numbering starts at the beginning of the edition and continues until its end
- <l> : numbering (re)starts at the beginning of each page
Note: In this way, it's possible to compare our edition with an reference edition.
| Elements | Numbering starts at : |
| <div> | parent node |
| <sp> | parent node |
| <p> | parent node |
| <lg> | parent node |
| <l> | each new page |
| <pb> | beginning of the edition |
2.3.3. type
This attribute is used to specify the type of the current <div>.
Note that for this attribute, the use of predefined values is restricted.
| Value | Usecase |
| titlePage | in the <front>, used for the title page of the work |
| privilege | in the <front>, used for the privilege of the work |
| castList | in the <front>, used for the cast list |
| liminal | in the <front>, used for any liminal part of the work |
| play | used at the beginning of a new play |
| act | used at the beginning of a new act |
| scene | used at the beginning of a new scene |
| part | used for any part of the work |
| subPart | used for any subpart (child of a type="part") of the work |
| letter | used for any letter |
| collection | used for any type of collection |
2.3.4. Recap table for attributes
| <text> | <div> | <lg> | <l> | <sp> | <p> | <pb> |
| xml:id | required | required | required | required | required | required | not required |
| n | not required | required | required | required | required | required | required |
| type | not required | required | not required | not required | not required | not required | not required |